

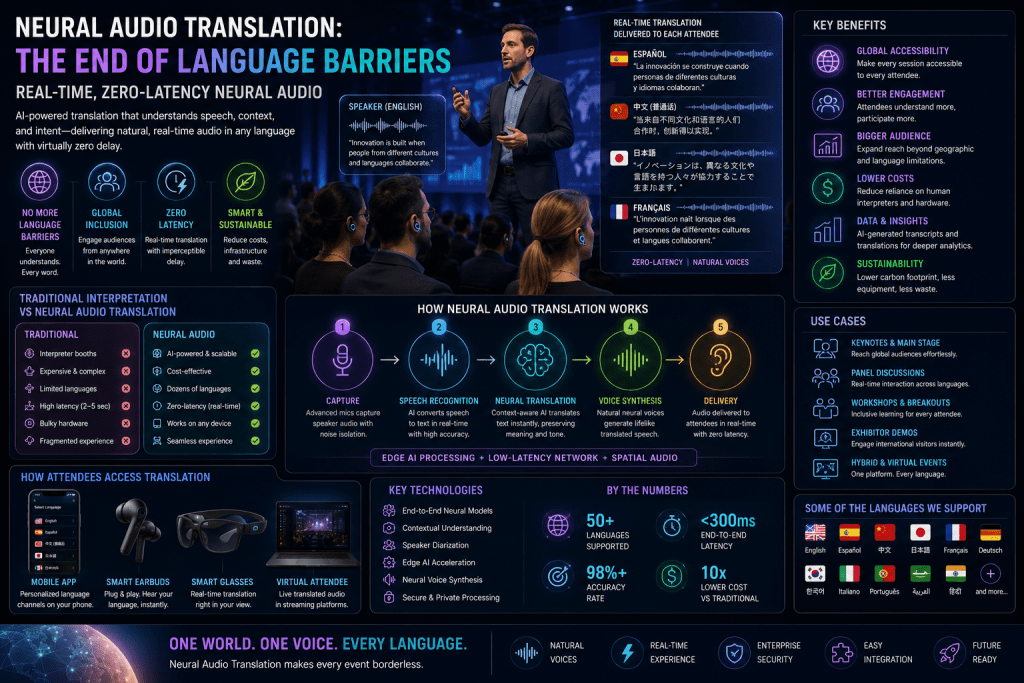
Language has always been one of the most significant operational barriers in global events. International conferences, trade shows, corporate summits, exhibitions, and hybrid experiences routinely bring together attendees, exhibitors, and speakers from dozens of linguistic backgrounds. Traditionally, overcoming these barriers required interpretation booths, radio-frequency headsets, multilingual staffing, and extensive translation logistics.
While these systems enabled basic multilingual communication, they often introduced delays, limited scalability, increased infrastructure costs, and fragmented attendee experiences.
Today, advances in neural audio translation, edge AI processing, spatial audio systems, and low-latency speech synthesis are fundamentally changing how multilingual communication functions inside event environments. Real-time neural audio translation systems are increasingly capable of delivering near-instantaneous spoken language conversion with dramatically reduced latency and significantly improved naturalness compared to traditional machine translation systems.
For the event industry, this marks the beginning of a major transformation in attendee accessibility, speaker reach, operational scalability, and global participation. Rather than treating translation as a separate service layer, neural audio systems are integrating multilingual communication directly into the event experience itself.
The result is a future where language barriers may no longer meaningfully restrict participation in international live events.
Why Traditional Event Translation Systems Are Becoming Insufficient
Conventional interpretation infrastructure was designed for earlier event formats with relatively static communication models.
Most large-scale events traditionally relied on:
- Simultaneous interpretation booths
- Human interpreters
- RF headset distribution
- Fixed language channels
- Manual translation workflows
While effective in many contexts, these systems introduce several limitations in modern event environments.
High Operational Complexity
Traditional interpretation setups require:
- Dedicated soundproof booths
- Specialized AV infrastructure
- Interpreter staffing
- Audio routing systems
- Headset logistics
- Technical coordination teams
For multilingual global events, operational complexity scales rapidly.
Limited Language Scalability
Adding additional languages often increases infrastructure and staffing requirements significantly.
As events become more internationally diverse, supporting large numbers of languages becomes financially and operationally difficult.
Audio Delay and Communication Friction
Even high-quality interpretation workflows introduce noticeable latency between original speech and translated audio.
This disrupts conversational flow during:
- Live Q&A sessions
- Interactive workshops
- Networking conversations
- Hybrid audience engagement
- Panel discussions
In highly interactive environments, latency becomes a major experience limitation.
Accessibility Challenges
Traditional systems also create usability friction through:
- Headset distribution bottlenecks
- Channel selection complexity
- Audio synchronization issues
- Limited support for informal interactions
These limitations reduce seamless participation across multilingual audiences.
What Is Neural Audio Translation?
Neural audio translation refers to AI-powered systems that combine speech recognition, neural machine translation, speech synthesis, and low-latency audio processing to convert spoken language into another language in near real time.
Unlike earlier rule-based translation engines, modern neural systems use deep learning models trained on massive multilingual datasets to preserve:
- Context
- Intent
- Tone
- Conversational flow
- Linguistic nuance
A complete neural audio translation pipeline typically includes:
- Automatic speech recognition (ASR)
- Neural machine translation (NMT)
- Voice synthesis systems
- Edge AI processing
- Spatial audio delivery
- Low-latency streaming infrastructure
These components operate simultaneously to generate continuous translated speech output.
The Technology Architecture Behind Zero-Latency Translation
Real-time neural translation depends on several advanced infrastructure layers working together with extremely low processing overhead.
Automatic Speech Recognition
The first stage involves converting live speech into machine-readable text.
Modern ASR systems use transformer-based AI models capable of:
- Speaker separation
- Accent adaptation
- Noise suppression
- Contextual language prediction
- Real-time transcription
Event environments are particularly difficult because of:
- Crowd noise
- Variable acoustics
- Multiple simultaneous speakers
- Stage audio interference
Advanced ASR models increasingly incorporate beamforming microphones and AI-powered noise isolation to improve transcription quality in live venues.
Neural Machine Translation
Once speech is transcribed, neural machine translation engines convert the text into target languages.
Modern NMT systems use large-scale transformer architectures capable of understanding:
- Semantic meaning
- Idiomatic expressions
- Industry terminology
- Contextual intent
- Conversational flow
Unlike older statistical translation systems, neural models generate more natural and contextually accurate outputs.
Some event platforms now support domain-specific language models optimized for:
- Medical conferences
- Technology summits
- financial events
- scientific symposiums
- legal presentations
This improves technical vocabulary accuracy significantly.
AI Voice Synthesis
The translated text is then converted back into spoken audio using neural text-to-speech systems.
Modern synthesis engines can generate highly natural speech with:
- Emotional tone adaptation
- Speaker pacing alignment
- Gender customization
- Accent localization
- Prosody preservation
Some systems are beginning to preserve elements of the original speaker’s vocal characteristics to create more authentic multilingual experiences.
Edge AI and Zero-Latency Processing
One of the most important breakthroughs enabling practical neural translation is edge computing.
Why Edge Processing Matters
Traditional cloud-based translation introduces network latency due to:
- Audio upload delays
- Remote processing overhead
- Network congestion
- Data routing latency
For live events, even small delays can disrupt conversational flow.
Edge AI systems move processing closer to the venue itself using localized compute infrastructure.
This dramatically reduces latency while improving reliability.
On-Site AI Translation Nodes
Modern event venues are increasingly deploying localized AI processing systems capable of handling:
- Real-time speech recognition
- Translation inference
- Voice synthesis
- Audio routing
directly within the venue network environment.
This enables near-instantaneous translation performance with greater operational stability.
Spatial Audio and Personalized Translation Delivery
Neural audio systems are also changing how translated speech is delivered to attendees.
Smart Earbuds and Wearable Translation
Instead of distributing traditional interpretation headsets, modern systems increasingly support:
- Bluetooth earbuds
- Smart glasses
- Wearable audio devices
- Mobile application streaming
Attendees can receive personalized language channels directly through consumer devices.
Spatial Audio Integration
Some advanced systems combine translation with spatial audio rendering.
This allows translated speech to appear directionally aligned with the speaker’s physical location on stage, improving immersion and cognitive comprehension.
AI Voice Personalization
Future systems may allow attendees to customize translation voice preferences based on:
- Accent familiarity
- Gender preference
- Speech pacing
- Accessibility requirements
This creates more personalized listening experiences.
Applications Across Event Environments
Neural translation systems are rapidly expanding beyond keynote interpretation.
Multilingual Networking
AI-powered conversational translation is increasingly being tested for attendee networking environments.
Wearable devices and mobile applications can support live multilingual conversations between attendees without requiring interpreters.
Hybrid and Virtual Events
Hybrid event platforms increasingly integrate live multilingual captioning and neural audio translation directly into streaming interfaces.
Remote participants can receive personalized language feeds instantly.
Exhibitor Demonstrations
Trade show exhibitors can use neural translation systems to support multilingual product demonstrations without maintaining large multilingual staffing teams.
Accessibility Enhancement
Real-time translation improves accessibility for global audiences while also supporting:
- Live captioning
- hearing assistance
- multilingual transcription
- language inclusivity
Operational and Business Impact
Neural audio translation creates several strategic advantages for event organizers.
Expanded Global Reach
Events can attract broader international participation without requiring large-scale interpretation infrastructure expansion.
Reduced Operational Costs
AI-based translation systems reduce dependency on extensive interpreter staffing and physical interpretation infrastructure.
Improved Attendee Experience
Lower latency and personalized delivery improve communication flow and engagement quality.
Richer Multilingual Analytics
AI translation systems generate valuable data regarding:
- Language demand patterns
- Engagement by language group
- Content interaction trends
- Global audience behavior
This supports better event strategy and audience targeting.
Challenges and Ethical Considerations
Despite rapid advancement, several limitations remain.
Accuracy Risks
Even advanced AI models may struggle with:
- Technical jargon
- Humor
- cultural nuance
- rapid conversational shifts
- overlapping speakers
Human oversight remains important in high-stakes environments.
Privacy and Data Governance
Real-time speech processing involves sensitive audio data collection requiring strong governance around:
- Voice data storage
- Consent management
- Translation logging
- Cross-border compliance
Voice Authenticity Concerns
Synthetic voice systems raise ethical questions regarding:
- speaker identity
- vocal cloning
- authenticity preservation
- consent for voice replication
Clear governance frameworks are increasingly necessary.
The Future of Neural Event Communication
Over the next several years, neural translation systems are expected to become more immersive, accurate, and integrated into smart venue ecosystems.
Emerging developments include:
- AI-preserved speaker vocal identity
- Emotion-aware translation systems
- AR subtitle overlays
- Real-time multilingual holographic avatars
- Brain-computer language interfaces
- Context-adaptive conversational AI
As processing speeds improve and AI models become more contextually sophisticated, real-time translation may eventually become nearly invisible within event experiences.
Conclusion
Neural audio translation is fundamentally reshaping multilingual communication within the event industry. By combining AI-powered speech recognition, neural machine translation, low-latency voice synthesis, and edge computing infrastructure, these systems are dramatically reducing the operational and experiential limitations of traditional interpretation models.
Their significance extends far beyond convenience. Real-time neural translation improves accessibility, expands international participation, reduces operational complexity, enhances attendee engagement, and enables more seamless communication across increasingly global event ecosystems.
Most importantly, this technology signals a future where language barriers may no longer define who can fully participate in live experiences. As neural translation systems continue evolving toward near-zero latency and human-level contextual understanding, multilingual communication may become an invisible layer within the next generation of intelligent event environments.